
Demo Video
About
RL-based post-training is a promising paradigm for aligning diffusion models with human preferences, and scaling rollout group size yields clear gains — but at prohibitive cost on large models like FLUX.1-12B. We propose Sol-RL (Speed-of-light RL), an FP4-empowered two-stage RL framework that decouples exploration from optimization: high-throughput NVFP4 rollouts generate a massive candidate pool, from which only the most contrastive subset is regenerated in BF16 for policy updates. This algorithm-hardware co-design accelerates rollouts while preserving training integrity. Experiments across SANA, FLUX.1, and SD3.5-L show superior alignment with up to 4.64× faster convergence.

Sol-RL enables efficient and high-fidelity text-to-image alignment.
Qualitative Results
All methods side by side. Click any image to view fullscreen.
Core Design: Decoupled Two-Stage Pipeline
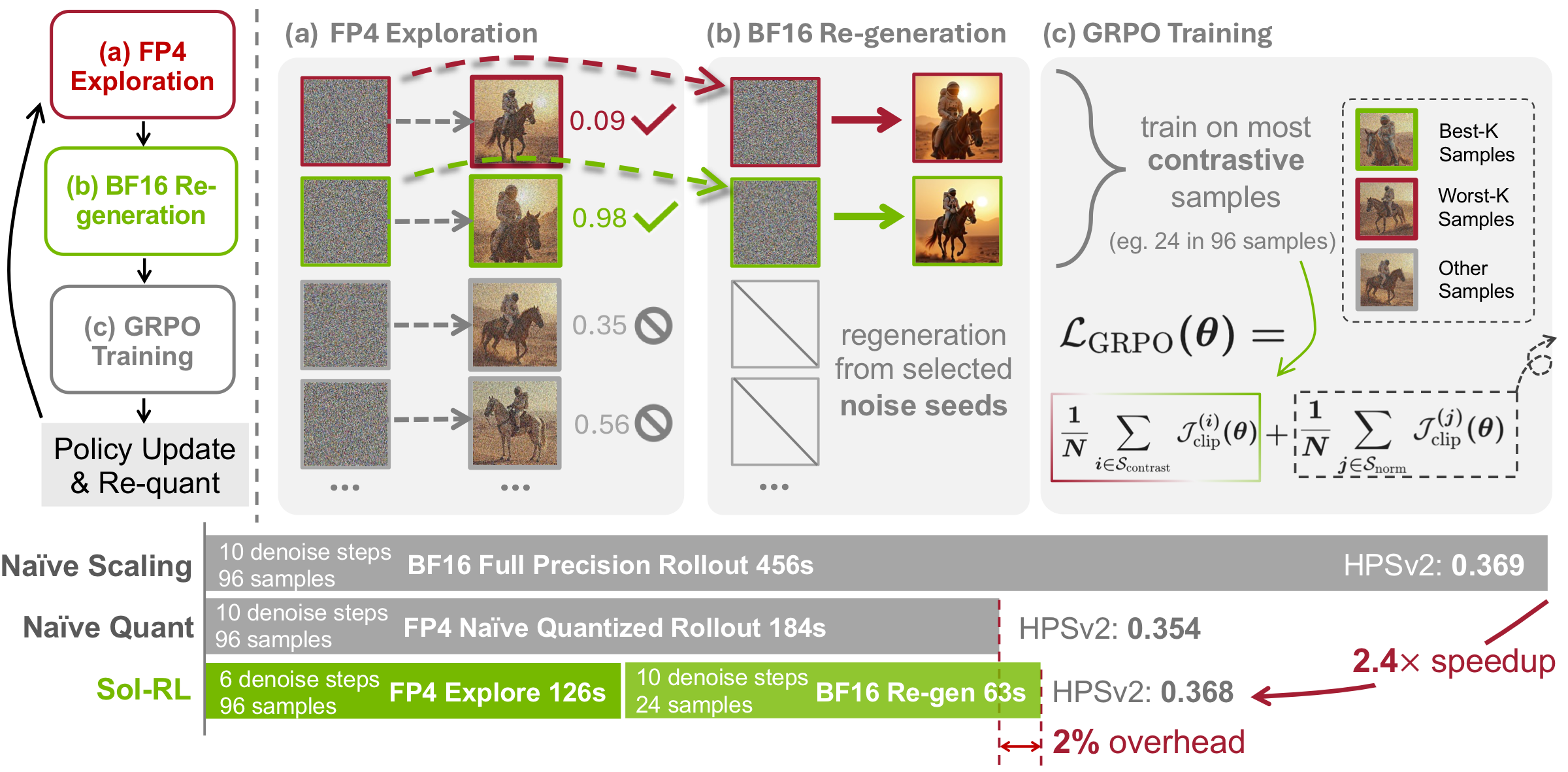
We decouple high-throughput FP4 exploration from selective BF16 training, achieving up to 2.4× rollout acceleration with merely 2% computational overhead while avoiding quantization-induced corruption.
Methodology
Scaling rollouts improves alignment but creates an inference bottleneck, and naive FP4 quantization compromises visual fidelity. Sol-RL introduces a decoupled two-stage architecture that uses FP4 exclusively for exploration while preserving BF16 for optimization.
Rollout Scaling: Promise and Bottleneck
Under selective training, only the best-K and worst-K samples drive gradient updates, so larger rollout groups yield better learning signals at fixed training cost. However, the vast majority of generated candidates are discarded — revealing massive redundancy in computing the full pool at high precision.
Key Insight: Proxy Reward Ranking via FP4
In ODE-style diffusion sampling, the semantic outcome is dictated by the initial noise seed. NVFP4 preserves this structure despite pixel-level deviations, so FP4 rollouts serve as reliable proxies for reward ranking — enabling us to identify the most informative seeds cheaply, then regenerate only those in BF16.
Two-Stage Pipeline
- Stage 1: FP4 Explore — Sample N=96 noises and generate candidates via the NVFP4-quantized solver (up to 4× TFLOPs vs. BF16) to compute proxy rewards. Filter to isolate the top/bottom-K most contrastive seeds.
- Stage 2: BF16 Train — Regenerate the selected K=24 seeds in BF16 with the full step budget. Optimize the policy on these high-fidelity samples, then re-quantize weights to NVFP4 for the next iteration.
In summary, Sol-RL harnesses FP4 throughput for massive-scale exploration and reserves BF16 compute strictly for the K samples that dictate the policy update — introducing merely ~2% overhead.
Overall Performance
Main Results on FLUX.1
| Method | ImageReward (Base w/o CFG: 0.455) |
CLIPScore (Base w/o CFG: 0.2630) |
PickScore (Base w/o CFG: 0.8096) |
HPSv2 (Base w/o CFG: 0.2566) |
||||
|---|---|---|---|---|---|---|---|---|
| Score | Δ (↑) | Score | Δ (↑) | Score | Δ (↑) | Score | Δ (↑) | |
| DanceGRPO | 1.4937 | +1.0387 | 0.2898 | +0.0268 | 0.8807 | +0.0711 | 0.3552 | +0.0986 |
| FlowGRPO | 1.5331 | +1.0781 | 0.2884 | +0.0254 | 0.8743 | +0.0647 | 0.3501 | +0.0935 |
| AWM | 1.6693 | +1.2143 | 0.3039 | +0.0409 | 0.8842 | +0.0746 | 0.3664 | +0.1098 |
| DiffusionNFT | 1.6707 | +1.2157 | 0.2991 | +0.0361 | 0.8852 | +0.0756 | 0.3613 | +0.1047 |
| Sol-RL (Ours) | 1.7636 | +1.3086 | 0.3089 | +0.0459 | 0.8932 | +0.0836 | 0.3688 | +0.1122 |
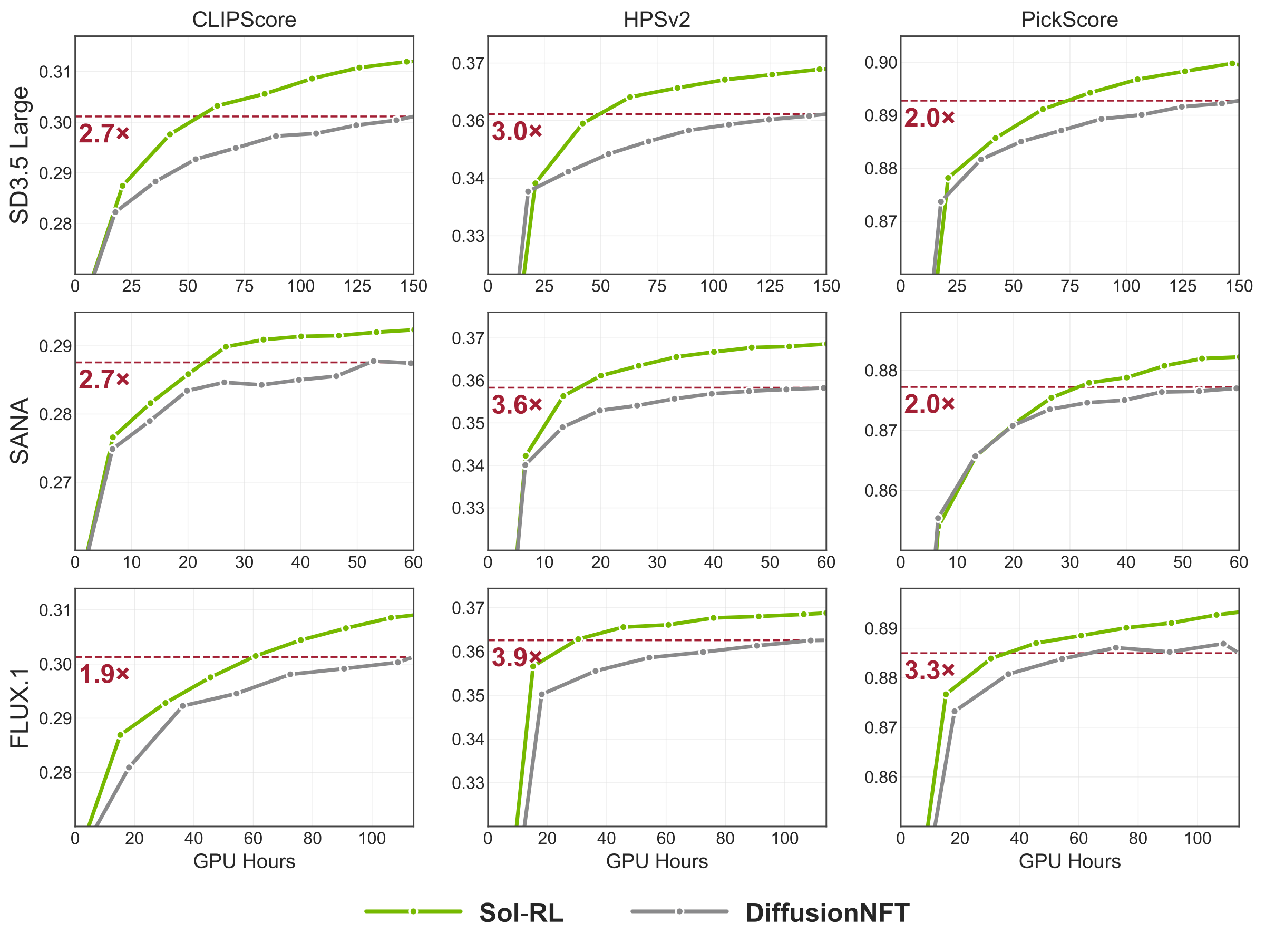
Learning curves across metrics and models.
Efficiency Comparison (seconds/iteration)
| Base Model | Rollout Naive | Rollout Ours | Speedup | E2E Naive | E2E Ours | Speedup |
|---|---|---|---|---|---|---|
| FLUX.1 | 184 | 79 | 2.33× | 274 | 169 | 1.62× |
| SD3.5-Large | 451 | 187 | 2.41× | 691 | 427 | 1.61× |
| SANA | 65 | 46 | 1.41× | 95 | 76 | 1.25× |